Designed for AI researchers
Focus on science, not infrastructure
Accelerate your research with seamless experiment tracking, efficient resource management, and powerful evaluation tools. Spend less time on infrastructure and more time on breakthrough discoveries.
Trust by AI Researchers from





Research challenges
Obstacles to breakthrough research
AI researchers face unique challenges that can slow down innovation and discovery. Clusterfudge helps you overcome these obstacles.
Experiment Tracking
Managing hundreds of experiments with different parameters and configurations leads to lost work and duplicated efforts.
Compute Access
Limited GPU availability creates bottlenecks, slowing down research progress and causing frustration when resources are unavailable.
Collaboration & Reproducibility
Sharing results and ensuring reproducibility across teams requires standardized environments and consistent tracking.
RunStreamlined Experiment Management
Launch experiments from anywhere, monitor progress in real-time, and iterate quickly. Clusterfudge Run gives you complete visibility into your experiments and infrastructure.
Rapid Iteration
Launch experiments with one click and iterate quickly with real-time feedback and monitoring.
Code Syncing
Automatically sync your code to remote machines, eliminating manual transfers and ensuring consistency.
Resource Management
Access GPUs when you need them with intelligent queuing and scheduling to maximize resource utilization.
EvalsRigorous Model Evaluation
Compare model performance across different versions and against published benchmarks. Track progress and identify areas for improvement with comprehensive evaluation tools.
Version Comparison
Track performance improvements across model versions to guide your research direction.
Standardized Benchmarks
Compare your models against industry benchmarks to understand your position in the field.
Publication-Ready Results
Generate comprehensive reports and visualizations for papers, presentations, and stakeholder updates.
ReportsResource Utilization Insights
Understand how your experiments use computational resources and identify optimization opportunities. Make data-driven decisions about resource allocation and future research directions.
Resource Monitoring
Track GPU utilization, memory usage, and power consumption to optimize your experiments.
Efficiency Analysis
Identify bottlenecks and inefficiencies in your training pipelines to speed up research cycles.
Research ROI
Demonstrate the impact of your research with clear metrics and visualizations for stakeholders.
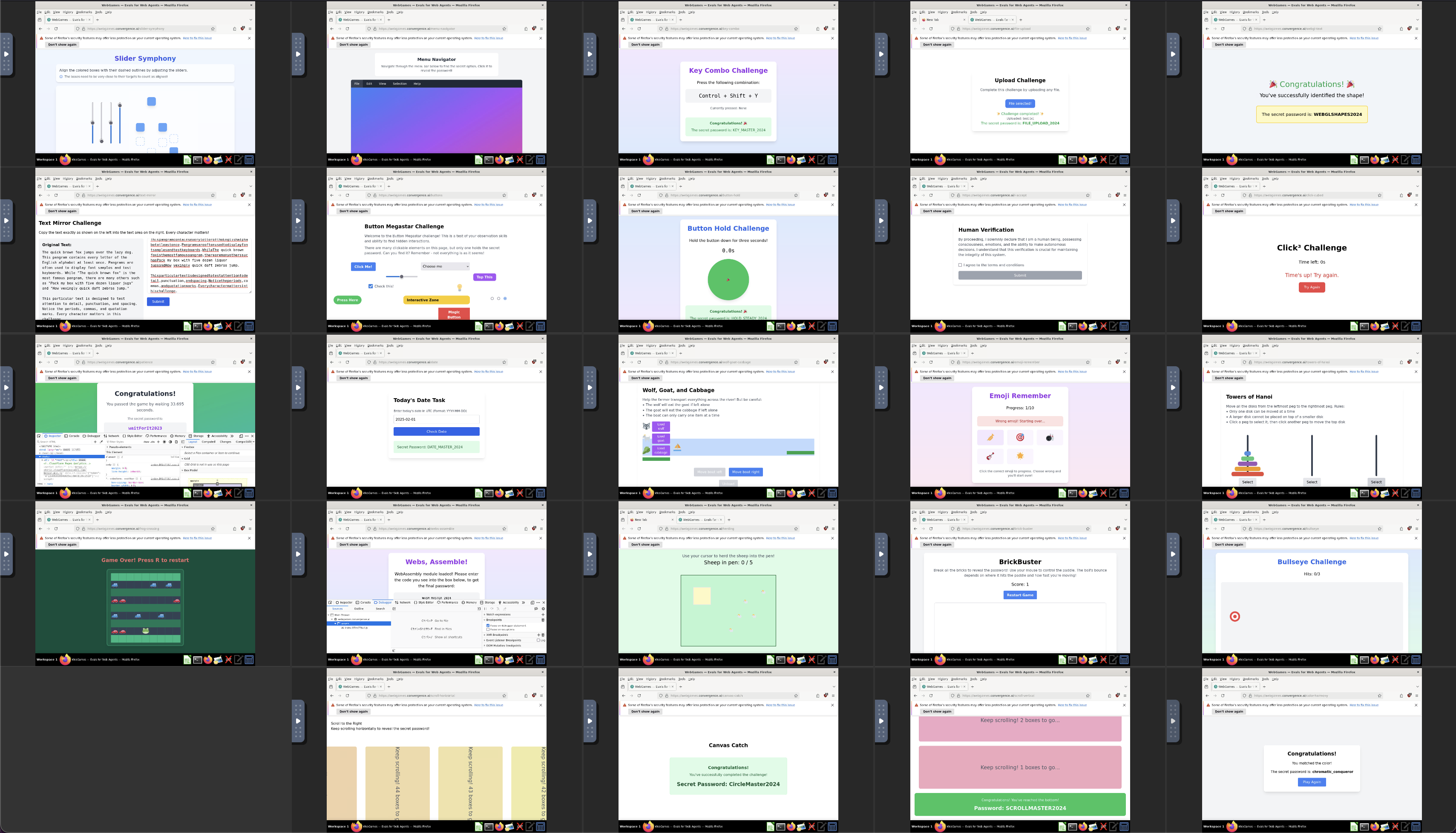
SandboxesSecure Agent Development
Build and test AI agents in secure, isolated environments. Clusterfudge Sandboxes provide the infrastructure for responsible agent development and evaluation.
Isolated Environments
Test agents in controlled environments with configurable security policies and access controls.
Research Reproducibility
Ensure consistent testing conditions across experiments for reliable and reproducible results.
Scalable Testing
Test agents across thousands of scenarios to ensure robust performance and identify edge cases.
Get started with Clusterfudge
Join leading AI labs using Clusterfudge to accelerate their research.